
James Kalbach
On Uncertainty in Information Architecture
Abstract
Uncertainty, in general, is a fundamental aspect of human activity and underlies much of our decision making. The notion of uncertainty in information seeking, in particular, dates back to Shannon and Weaver (1949) and since then has been investigated in many forms. Kulthau’s (1993) work on information uncertainty is perhaps the most extensive. Through two specific examples, this article proposes uncertainty as a unifying heuristic in information architecture. Measurements of uncertainty can serve a diagnostic function in both the design and evaluation of information technologies and user interfaces. As a relatively new field of practice and study, information architecture borrows from established disciplines, such as computer science, human-computer interaction, and graphic design. Historically, library and information science (LIS) has proven to be a major source of guidance and of inspiration. For instance, existing knowledge from LIS on controlled vocabularies and facets informs thought on those subjects in information architecture. Borrowing from prior research in information-seeking behaviour, this essay explores the idea of identifying a common, overarching principle in information architecture: uncertainty.
On Uncertainty
Uncertainty, in general, is a broad concept that has been investigated in many fields, such as decision-making (Harris 2008), ethics (Tannert 2007), risk and business (Hubbard 2007), and even physics (e.g., Heisenberg’s Uncertainty Principle), among numerous other areas. Indeed, the notion of uncertainty underlies most aspects of our lives: it has been show to drive everything from trading on stock markets to deciding which piece of fruit to buy at the market.
Formal associations between information, in particular, and uncertainty date back to Shannon and Weaver (1949), fathers of modern information and communication theory. For one, they proposed and popularized the concept of “information entropy”. or the measure of uncertainty in a transmitted message. Overall, they believed that the presentation of information reduced uncertainty: the more information a person received, the lower their uncertainty.
Other researchers picked up on uncertainty in information science. For instance, Nicholas Belkin (1980) focused on the notion that seekers — sometimes even experts in a given information system — are not able to properly formulate queries to access the information they need. He calls this “anomalous states of knowledge”. or ASK for short. Here, uncertainty underlies the basic information seeking. Kuhlthau’s (1993) work on uncertainty and information seeking is perhaps the most extensive. She proposes uncertainty as a fundamental principle in her Information Search Process (ISP), a six-stage model of seeking information. She describes the role of uncertainty as follows:
Uncertainty is a cognitive state that commonly causes affective symptoms of anxiety and lack of confidence. Uncertainty and anxiety can be expected in the early stages of the ISP. The affective symptoms of uncertainty, confusion, and frustration are associated with vague, unclear thoughts about a topic or problem. As knowledge states shift to more clearly focused thoughts, a parallel shift occurs in feelings of increased confidence. Uncertainty due to a lack of understanding, a gap in meaning, or a limited construct initiates the process of information seeking. (Kuhlthau 1993, p. 111)
Two interesting aspects emerge from this perspective. First, Kuhlthau found that uncertainty is often the primary driver for the affective states people while seeking information. Any endeavor to understand uncertainty in information seeking must therefore also account for the seeker’s affective states. Kuhlthau’s model does just this, along with considerations of cognitive states and physical actions taken.
Second, Kuhlthau shows that contrary to previous models of uncertainty in communication, the introduction of new information can increase uncertainty. This is not always the case, but it holds true in complex information seeking situations. In Kuhlthau’s model, uncertainty initiates information seeking, and it may also return, typically occurring in earlier stages of the search process (fig. 1).
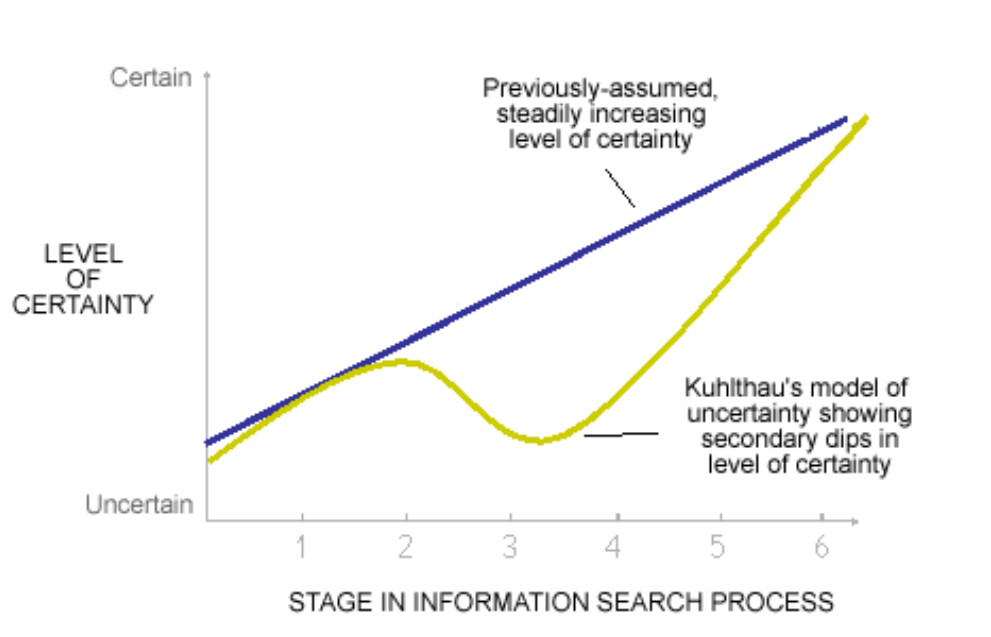
Figure 1. Prior models of uncertainty and information assumed the more information a person receives, the lower their uncertainty. Kuhlthau’s research shows that uncertainty can return in the process of seeking information, with dips of confidence occurring in earlier stages.
Complex search situations are generally associated with uncertainty. However, it is the perception of complexity, rather than the actual objective complexity of a task, that causes feelings of uncertainty (Kuhlthau 1999). Perceived complexity is often the cause of the secondary peak of uncertainty, doubt, and confusion in information seeking. Unfortunately, many web-based search devices compound the perception of complexity by overwhelming the user with “everything”. when a few well-chosen guiding elements might be more appropriate for orientation. Advances in information technology and the advent of ubiquitous web-based search and navigation systems have only compounded the user’s dilemma rather than eased it.
In a very comprehensive study, Wilson et al. (2002) also explored the relationship between uncertainty and information seeking. Based on longitudinal data collected in the U.S. and U.K., the researchers show that uncertainty can be operationalised and reliably measured in a quantitative investigation. They found that the principle of uncertainty as outlined by Kuhlthau indeed serves as a useful variable in understanding and predicting information-seeking behavior. The research points towards uncertainty as a universal aspect of information seeking.
Furthermore, although uncertainty is often associated with risk and danger, Theresa Anderson (2006) reminds us that uncertainty can also have positive effects. She found uncertainty to be necessary and even desirable in many situations: it can motivate new lines of inquiry, contribute to creative thinking, and spur innovation. Anderson shows us that uncertainty is indeed a very complex aspect of human nature, and it is the interplay between desired and undesired forms of uncertainty that should draw interest in information research.
Information Architecture
In associating information architecture and uncertainty, then two questions arise. The first question is, do existing models of general information seeking apply to the online information spaces—a primary area of focus for modern information architecture? Evidence suggests that this is the case. For instance, Choo, Detlor, and Turnbull (2000) examined information seeking on the web and developed an integrated model of browsing and searching based on established research, specifically Ellis’s (1989) behaviors. The researchers successfully map Ellis’s general behavioral framework onto information seeking on the web. It is reasonable to assume, then, that uncertainty in information seeking can equally apply to online environments like the web.
The second question is, if uncertainty is such a broad concept, what particular relevance might if have on the practice of information architecture? Two specific examples help answer this question:
- Uncertainty in breadth versus depth of hierarchical menus
- The scent of information and labeling
Each is discussed below in more detail.
Uncertainty in Breadth vs. Depth
An example of information uncertainty can be found in the issue of breadth vs. depth of information structures, an important issue in information architecture. This refers to the ration of the number of visible menu items in a given navigation to the number of hierarchical levels in the structure of the information being accessed. Given a fixed number of information objects (e.g., documents or web pages), there is a dependency between the two: the fewer the options presented in the interface, the deeper the structure, and vice-verse.
In investigating breadth vs. depth, researchers typically have studied search time, disorientation, error rates, and even satisfaction. A good summary can be found in Larson and Czerwinski (1998). The general design recommendation from such research is to increase breadth to reduce search time and errors, as well as increase satisfaction. It is believed that the time spent scanning menu items in a broader structure is less than the time spent drilling down into a deeper structure. In the latter, menu terms are necessarily more general and therefore more ambiguous.
Unfortunately, most breadth vs. depth studies test relatively symmetrical structures, for example 4x4x4 structures (Snowberry et al. 1983), and thus do not account for naturally occurring irregularities in hypertext shapes. One exception is a study by Norman and Chin (1988), in which constant structures were compared to irregular shapes (increasing, decreasing, convex, concave). The researchers found that the concave structure (8x2x2x8) performed best.
Bernard (2002) tested information structures with both symmetrical and asymmetrical schemes as well. He confirmed that broader structures do indeed perform better, but also found that deeper, asymmetrical structures perform better than symmetrical structures of the same depth. For example, 4x4x4x4 structures performed not only worse than asymmetrical shapes of the same depth (e.g. the concave 6x2x2x12) but also worse than deeper concave structures (e.g. 3x2x2x2x12). He concludes that the performance of the structures is determined in part by the properties of the hypertext shape, namely the perceived complexity of the information space and information uncertainty.
A concave information architecture indeed seems to match a decrease in certainty users often experience when seeking information as described by Kuhlthau. At the top level of a concave structure, seekers need orientation without being overwhelmed. A balance of well-selected, mutually exclusive categories serves as an efficient, satisfying starting point. The middle levels are best restricted in breadth, thus reducing uncertainty and feelings of doubt or frustration while making choices. The broader, bottom level of a concave structure, however, provides maximum information scent and a sense of “arrival” as the seeker begins gaining confidence again. As Bernard (2002) writes, “at the terminal level, broad menus reduce the information uncertainty”. At this point in the structure the users are able to handle more complexity.
Conversely, convex structures present more choices at the middle levels than on the ends (e.g. 2x8x8x2) and thereby contradict a normal pattern of cognitive and emotional user needs in information seeking: there is more uncertainty after navigating has begun. This could mean an increased likelihood of a hesitation in the search process, and feelings of apprehension and frustration may set in. Therefore, the performance of varying hypertext shapes appears to be given not only by breadth vs. depth, but also perceived complexity and uncertainty. In evaluating or creating information architectures, uncertainty as well as affective considerations can play a potential role in predicting their overall success.
Uncertainty and Information Scent
Spool et al. (2004) popularized the notion of the scent of information in web navigation base on empirical research with web users. Derived from Information Foraging Theory (Pirolli & Card 1995), information scent refers to how well links and navigation options match a visitor’s information need and how well they predict the content on the destination page. It really has to do with creating a sense of confidence in navigating. The researchers explain:
Usually … scent is invisible. It is a product of how well the designers understand the site’s users, those users’ needs, and how the users access the site. In fact, the best way to detect scent is to measure the users’ confidence. When the scent is weak, users are not confident at all. They doubt their choices. They tell us they are making “wild guesses”. They click hesitantly, hoping the site will magically come through for them. More important, they rarely find what they are seeking. When scent is strong, however, their confidence builds as they draw closer to their content. They traverse the site with little hesitation. Moreover, they find what they are seeking.
Information scent, as Spool et al. propose it, is about how uncertain a person is when navigating a website. The notion of trigger words emerges as the most critical aspect in this respect in his model. These are labels and texts that match a visitor’s need. And indeed, scanning for trigger words is a consistent pattern Spool and his team found across user types, across tasks, and across sites during their research:
We’ve noticed that people looking for information all exhibit similar patterns. They first scan for their trigger words—words or phrases they associate with the content they’re seeking—in an attempt to pick up the scent.
Trigger words help to indicate they are on the right track, and they appear to reduce uncertainty and give confidence in navigating further.
Getting the right labels seems to be critical to reducing information uncertainty, but it is often an underestimated part of the design process. The difficulty in creating labels that match users’ information needs—and thereby reducing uncertainty—lies in the variation in terms people use to describe the things they are looking for. Research shows that the chances of two people naming the same thing the same way are low. Furnas et al. (1987), then researchers at Bell Labs, researched this issue and explain:
The fundamental observation is that people use a surprisingly great variety of words to refer to the same thing. In fact, the data show that no single access word, however well chosen, can be expected to cover more than a small proportion of user’s attempts.
In many tests with hundreds of people across different situations and subject areas, they found that a single access point (i.e. a term chosen for navigation) will at best match user’s terms only 10-20 percent of the time.
Furthermore, there are potentially many aspects of navigation design that contribute to scent, including position on screen, labels, icons, color, descriptive texts, and so forth. But ultimately scent is more complex and subtle than how links are displayed. Garret (2002), author and a leader in the information architecture community, reflects on the importance of this overall context based on his personal experience:
All the information users have to go on are the language of the link, its visual treatment, and its placement on the page. Yet, despite this extreme shortage of information, they somehow develop mental images of the result they’ll get when clicking a link. The mental image might not literally be a picture of the page in their minds—although if they’re visual thinkers, it may take exactly that form. They may have formed a mental impression of the content and the manner of its presentation. This impression isn’t derived solely from the information they have gleaned from the navigation design, though. They also take their own experience into account.
In designing a system of navigation, information architects have a range of tools to reduce potential uncertainty at their disposal. Chief among these are labels. But as Garrett postulates, there potentially are many other subtle clues people use to effectively navigate. From the standpoint of the topic of this article, the tools to use and what design techniques to employ should be driven by the aim of reducing uncertainty.
Conclusions
Information seeking, on the web in particular, can be an emotional experience. Unfortunately, confusion and doubt tend to dominate feelings of enthusiasm and optimism. The joy of discovery and pride of learning can be rare feelings against a backdrop of frustration and a sense of being overwhelmed, even for expert searchers. In general, people using web-based search systems to learn about a given topic have difficulty, particularly in the early phases of information seeking (Sullivan 2000) Further, while examining causes of user frustration on the web, Lazar et al. (2003) found that up to one-half of the time spent in front of the computer is wasted due to frustrating experiences. Uncertainty is at the heart of these frustrating experiences.
I introduce uncertainty as an underlying heuristic in information architecture. Through two examples—breadth vs. depth and information scent—I’ve showed how uncertainty can be associated with core aspects of information architecture. A common goal in information architecture, then, is to design information environments that lower negative uncertainty. On the other side of that coin, information architecture also needs to recognize when positive forms of uncertainty can be helpful in someone’s information experience. In the end, measures of uncertainty should serve as a diagnostic characteristic in both building and evaluating information architectures in the future. Knowing and when users of an information system have moments of uncertainty point to the need for improvement and better design solutions.
References
- Anderson, T.D. (2006) “Uncertainty in action: observing information seeking within the creative processes of scholarly research”. Information Research, 12(1) paper 283. http://InformationR.net/ir/12-1/paper283.html.
- Belkin, N. J. (1980) Anomalous states of knowledge as the basis for information retrieval. Canadian Journal of Information Science, 5, 133-143.
- Bernard, M. L. (2002) Examining the effects of hypertext shape on user performance. Usability News, 4.2. http://wsupsy.psy.twsu.edu/surl/usabilitynews/42/hypertext.htm.
- Bessiere, K., Ceaparu, I., Lazar, J., Robinson, J., and B. Shneiderman (2002) Understanding computer user frustration: Measuring and modeling the disruption from poor designs. Under review. ftp://ftp.cs.umd.edu/pub/hcil/Reports-Abstracts-Bibliography/2002-18html/2002-18.html.
- Choo, C. W., Detlor, B., and D. Turnbull (2000) Information seeking on the web: An integrated model of browsing and searching. FirstMonday, 5(2). http://outreach.lib.uic.edu/www/issues/issue5_2/choo/.
- Ellis, D. (1989) A behavioural model for information retrieval system design. Journal of Information Science, 15 (4/5), 237-247.
- Ellis, D., Cox, D., and K. Hall (1993) A comparison of the information-seeking patterns of academic researchers in the physical and social sciences. Journal of Documentation, 49(4), 356-369.
- Ellis, D. and Haugen, M. (1997) Modelling the information seeking patterns of engineers and research scientists in an industrial environment. Journal of Documentation, 53(4), 384-403.
- Furnas, G., Landauer T.K., Gomez, L.M., and S. Dumais (1987) “The Vocabulary Problem in Human-System Communication”. Communications of the ACM 30 (11), 964.
- Harris, R. (2008) “Introduction to Decision Making”. http://www.virtualsalt.com/crebook5.htm.
- Hubbard, D. (2007) How to Measure Anything: Finding the Value of Intangibles in Business. John Wiley & Sons.
- Garret, J. J. (2002) “The Psychology of Navigation”. Digital Web Magazine. http://www.digital-web.com/articles/the_psychology_of_navigation/.
- Kuhlthau, C.C. (1991) Inside the search process: Information seeking from the user’s perspective. Journal of the American Society for Information Science, 42(5), 361-371.
- Kuhlthau, C. C. (1993) Seeking meaning: A process approach to library and information services. Ablex.
- Kuhlthau, C.C. (1999) The role of experience in the information search process of an early career information worker: Perceptions of uncertainty, complexity, construction, and sources. Journal of the American Society for Information Science, 50(5), 399-412.
- Larson, K. and Czerwinski, M. (1998) Web page design: Implications of memory, structure and scent from information retrieval. Proceedings of the Associations for Computing Machinery’s CHI 1998, 18-23.
- Lazar, J., Bessiere, K., Ceaparu, I., Robinson, J. and B. Schniederman (2003) Help! I’m lost: User frustration in web navigation. IT & Society, 1(3), 18-26. http://www.stanford.edu/group/siqss/itandsociety/v01i03/abstract.html#2.
- Marchionini, G. (1995) Information seeking in electronic environments. Cambridge University Press.
- Meho, L.I. and Tibbo, H.R. (2003) Modeling the information-seeking behavior of social scientists: Ellis’s study revisited. Journal of the American Society for Information Science and Technology, 54(6), 570-587.
- Pirolli, P. and Card, S. (1995) Information foraging in information access environments. Human factors in computing systems: Proceedings of CHI 95. http://www.sigchi.org/chi95/Electronic/documnts/papers/ppp_bdy.htm.
- Shannon, C.E. and Weaver, W. (1949) The mathematical theory of communication. University of Illinois Press.
- Snowberry, K., Parkinson, S., and N. Sisson (1983) Computer display menus. Ergonomics, 26, 699-712.
- Spool, J., Perfetti, C., and Brittan, D. (2004) Design for the Scent of Information. User Interface Engineering [report], 2.
- Sullivan, D. (2000) Search satisfaction and behavior results released. The Search Engine Report (April 4). http://en.wikipedia.org/wiki/Uncertainty - cite_ref-embo1_2-0
- Tannert, C., Elvers, H.D., and B. Jandrig (2007) The ethics of uncertainty. In the light of possible dangers, research becomes a moral duty. EMBO Rep. 8 (10): 892–6. http://www.nature.com/embor/journal/v8/n10/full/7401072.html.
- Wilson, T.D., Ford, N.J., Ellis, D., Foster, A.E. and A. Spink (2002) Information seeking and mediated searching: Part 2. Uncertainty and its correlates, JASIST 53,9: 704-715.
