
Luigi Spagnolo, Davide Bolchini, Paolo Paolini & Nicoletta Di Blas
Beyond Findability
Search-Enhanced Information Architecture for Content-Intensive Rich Internet Applications
Abstract
This paper details a way to extend classic information architecture for web-based applications. The goal is to enhance traditional user experiences, mainly based on navigation or search, to new ones (also relevant for stakeholders’ requirements). Examples are sense making, at a glance understanding, playful exploration, serendipitous browsing, and brand communication. These new experiences are often unmet by current information architecture solutions, which may be stiff and difficult to scale, especially in the case of large or very large websites. A heavy reliance upon search engines seems not to offer a viable solution: it supports, in fact, a limited range of user experiences. We propose to transform (parts of) websites into Rich Internet Applications (RIAs), based, beside other features, upon interaction-rich interfaces and semantic browsing across content. We introduce SEE-IA (SEarch-Enhanced Information Architecture), a coherent set of information architecture design strategies, which innovatively blend and extend IA and search paradigms. The key ingredients of SEE-IA are a seamless combination of structured hypertext-based information architectures, faceted search paradigms, and RIA-enabled visualization techniques. The paper elucidates and codifies these design strategies and their underlying principles, identifying also how they support a set of requirements which are often neglected by most current design approaches. A real case study of a complex RIA designed for a major institutional client in Italy is used to vividly showcase the design strategies and to provide ready-to-use examples that can be transferred to other IA contexts and domains.
Introduction
This paper is about design strategies for large, or very large, content-intensive websites. In almost two decades, improvements in web engineering have brought us from small websites - made of a few, static pages - to large, dynamic, information-intensive web applications. The advances in technical infrastructures have made possible a high level of scalability of these web applications, and a number of design methodologies (Garzotto & Paolini 1993; Rossi et al. 2001; Ceri et al. 2002; Quintarelli, Resmini & Rosati 2007; Koch et al. 2008) have been developed to conceptually structure and organize the content in various contexts and domains. At the beginning, the “homepage” was the main index, linked to a few pages, but over time the notion of “Information Architecture” (Rosenfield & Morville 2006) emerged: i.e. how to organize a large amount of information (hundreds or thousands of pages) to provide an optimal user experience.
In this paper we focus on large, content intensive-websites (typically meant for education, cultural, leisure or other complex knowledge needs) where different types of information are interconnected in a web-like structure. There are domains, including digital libraries and archives notably, that do handle large amounts of information, but with different paradigms: they have a few types of information items (e.g. ‘book’, ‘document’, etc.) and searching for items according to a set of criteria is the most typical user experience. Even in situations where the need for exploratory search is advocated (Bates 18; Hearst, Smalley & Chalder 2003; Marchionini 2006) the concept of retrieving and manipulating sets of items from a repository remains the main interaction paradigm of interest.
For “hypertext-websites” (and we remind the reader that the web was originally conceived as a hypertext technology), more complex organizations (information architectures) are needed to serve a broad variety of purposes, which fulfill important requirements for the user experience. From the user point of view, a content-intensive web application should fulfill the requirements listed below:
- Usability: the application should respond to overall criteria of usage efficiency and effectiveness as well as user satisfaction. This is a very general requirement, common to any kind of software application.
- Findability (Morville 2007): the ability for the user to easily locate what she is looking for. This requirement is common to digital libraries, archives, information bases and the like, where information retrieval is the main user experience. Information seeking needs may include (i) searching for a specific piece of knowledge, knowing exactly what to look for, (ii) locating something that the user cannot easily name or describe (e.g. “who is the famous author of a photograph in which a kissing couple is reflected inside a car mirror?”), or even (iii) an extremely vague desire of exploration (“let’s browse around to find something interesting”).
- “At a glance” sense making: the user can immediately understand the coverage of the website and the relative importance of the topics, being aware of the current context of exploration.
- Playful exploration: users are engaged and compelled to “stay and play,” being able to playfully interact with the application and learn from it, by putting in relation concepts and pieces of information (painter - work of art - artistic movement - similar works of art etc.).
Moreover, other requirements come from the website stakeholders. In particular, an institution or corporation, when communicating to its audience via a website, may need the following:
- Serendipity (Weinberger 2007): the possibility of promoting crucial contents so that users can stumble and get interested in them (even if they were not looking for that kind of information).
- Communication strength and branding (Bolchini, Garzotto & Paolini 2008; Bolchini, Garzotto & Sorce 2009): ensuring that the intended message(s) of the website and the “brand” of the institution behind it are clearly perceived by the user.
While in some cases the above requirements reinforce each other, in other cases they may be in contradiction. Those who argue in favor of usable websites, for example, often advocate simplistic information organizations that fail to meet the requirements of information intensive websites. Structured architectures are needed to organize large content, but they also tend to be quite “opaque” and rigid in terms of findability, serendipity, and overall usability (Crystal 2007; Weinberger 2007; Morville & Callender 2010). High-impact branding is a requirement that is typically dealt with mainly at the homepage level but does not affect the overall structure of the application (Bolchini, Garzotto & Paolini 2007).
A different approach to the problem is provided by search mechanisms: users can directly formulate a request to find what they are looking for. In fact, search is often the only way to locate the desired information within a (very) large website. A total reliance on the search paradigm, however, seems suitable for applications like digital libraries, archives and alike only, where (more or less traditional) information retrieval is the main user experience. When complex and articulate requirements are at stake (Bolchini, Garzotto & Paolini 2007; Bolchini, Garzotto & Paolini 2008; Bolchini, Garzotto & Sorce 2009) - as it is the case with most information-intensive hypertext-web applications - search alone is not sufficient. How can a user grasp ‘at a glance’ the spectrum of the content? How can a user, who is not looking for a specific item, access and explore the content? How can web designers suggest to the user what is worth exploring? How can users “stumble” into something the existence of which they did not even suspect?
To address these issues, the perspective on information architecture that we embrace in this paper is the conceptual modeling of the user experience, i.e. the systematic, high-level characterization of the user-perceivable features of the design that have a direct impact on the quality of the user interaction and are fairly agnostic of the specific implementation techniques used.
SEE-IA: A Proposal
To tackle these challenges, this paper introduces SEE-IA (SEarch-Enhanced Information Architecture - pronounced “see ya”), an integrated set of RIA-enabled interactive design strategies that leverages existing patterns, such as faceted navigation and search (Hearst 2009; Tunkelang 2009; Morville & Callender 2010), and properly integrates them with engineered information architectures.
The contribution of this paper does not lie in the idea of combining search mechanism and information architecture (this kind of approach already exists: e.g. see Sacco 2006; Crystal 2007), but in an integrated set of RIA-enabled design strategies to support important requirements for the user experience. SEE-IA focuses on a specific group of RIAs: applications seamlessly integrating complex information architecture with search mechanisms and advanced interactive interfaces.
SEE-IA proposes a set of integrated RIA-enabled design strategies (fig. 1) that meet much-needed requirements for the user experience in large, content-intensive web applications. The constituent strategies of the approach provide RIA-based ways to blend faceted search with information architecture design to allow for not only “traditional” findability but also serendipity, “at a glance” sense making, and playful exploration. Strategies for properly communicating introductory content over a collection of information are also proposed, to enhance branding and communication strength.
The unique feature of SEE-IA lies not in the individual design components (which can be found in other approaches as well) but in the seamless combination of these elements to give vent to meaningful user experiences, and fulfill a variety of difficult to address, but crucial requirements.
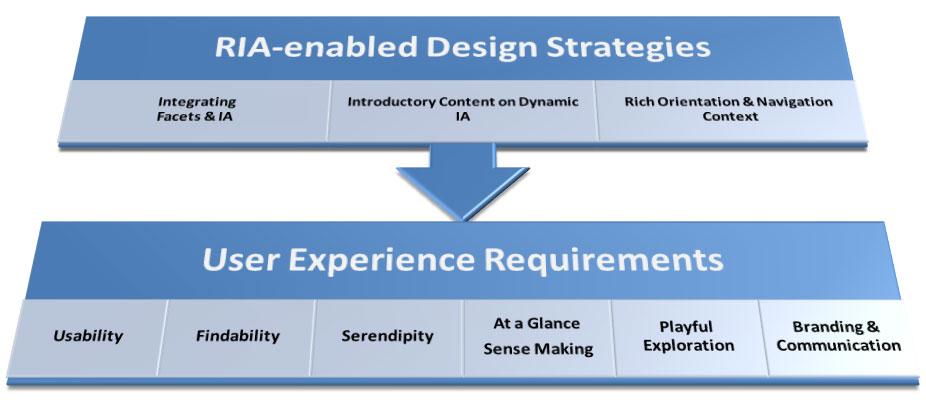
Figure 1. The top bar indicates the RIA-enabled design strategies that will be introduced in this paper. The lower bar indicates some crucial requirements that these design strategies can effectively support.
To vividly illustrate the components of SEE-IA, we will make reference to a real-life case study: the new website (with advanced RIA features) for Direzione Generale per le Antichità (Directorate-General for Antiquities), the branch of the Italian Ministry of Culture managing archeology and antiquity. The website is expected to become public in Fall 2010 (at content’s completion). Intended users include professionals who are working in the Ministry or with the Ministry, scholars, amateurs, educators and pupils, journalists and ordinary people interested in archeology. The variety of user categories suggests that two extremes must be avoided: the rigid structure provided by traditional information architectures and a “generic” search engine. In addition, the site is not intended to be a digital library or an archive of archeology (the ministry has other efforts for this); therefore straight information retrieval is not a desirable model for the user experience. Serendipity, findability, at a glance sense-making, playful exploration, communication impact, and branding (fig. 1) are considered important requirements that still need to be coupled with effectiveness, efficiency and usability. We will introduce the general challenges and innovative RIA-based design strategies of our approach, followed by examples of solutions illustrated through screenshots and mock-ups from the new website. We warn the reader that, obviously, it is impossible to fully reproduce on a printed paper the “look and feel” provided by a highly dynamic RIA.
Integrating Faceted Search with Information Architecture
Imagine a very large website, with thousands of items such as Novels, Movies and Comics. From an architectural perspective, these items can belong to different types and can be linked in different ways: for example, “movies” are connected to “actors,” while “novels” are not. A classical information architect can create groupings like “all fictional works”, “all novels”, “all movies”, “novels by genre” (drama, comedy), “movies by genre”, “novels by period” (contemporary, middle age, ancient), “movies by audience” (family, children, adults) and arrange the access structures in a single overall hierarchy (fig. 1).
This traditional information architecture fails to acknowledge the fact that all the above items could be grouped in the user’s mind into the broad category of “entertainment media” and transversally explored as such. In fact, combining classifications (e.g. looking for a detective novel settled in 150s) would require nesting them, forcing designers to make one classification criterion (e.g. the type of resource: novels, books, etc.) prevail over the others, by making it the only starting point for navigation.
Multiple hierarchical schemas with overlapping content may be a solution, but the “offer” to the user would be quite confusing since different combinations would be cumbersome to try. Another possibility could be a search engine, but that would fail to support other important requirements such as brand communication or serendipity.
A third option could be a juxtaposition of standard information architecture and a standard search engine. This solution, however, although better than nothing, is not optimal, since it cannot support a seamless user experience.
We propose instead to embed into traditional information architecture a more suitable search paradigm, namely faceted navigation (Yee et al. 2003; Hearst 2009; Morville & Callender 2010), also frequently known as a faceted search (when complemented by keyword-based search: Sacco 2006; Tunkelang 2009) to obtain dynamic access structures to information (Sacco 2006). In Figure 3, we show how that situation above described could be more suitably modeled.

Figure 2. A traditional hierarchical index: rigid taxonomy to access information
The following concepts (Bolchini & Paolini 2006) are at the basis of our design strategy:
- Topics: content items, possibly structured, covering a specific subject (e.g. an “artist’s biography” or “about us”).
- Multiple topics: content items, possibly structured, with several instances in the same website. Examples could be "novels,” “movies,” “comics” (fig. 3). The concept is analogous to, but not the same as the notion of “class” in object-oriented programming.
- Sets of topics: collections of instances of multiple topics. They are in all respects sets, and can therefore have supersets, subsets, as well as intersections, unions, complements, etc. Set of instances, for example of "novels,” “movies,” “comics” could be reorganized into the superset “interactive media. Some “facets” are common to all the entertainment media superset elements (“popularity,” “year,” “genre,” “setting,” “audience”) while others are specific to a certain type of media only (e.g. “actor” applies only for movies, while “graphical style” only for comics).
One or several access and visualization strategies (fig. 3) can be applied to the sets of topics. From the homepage, for example, users may be allowed to access a list of all the “entertainment media” or just “top of the week” highlights. Both of these sets could be filtered using suitable search mechanisms.
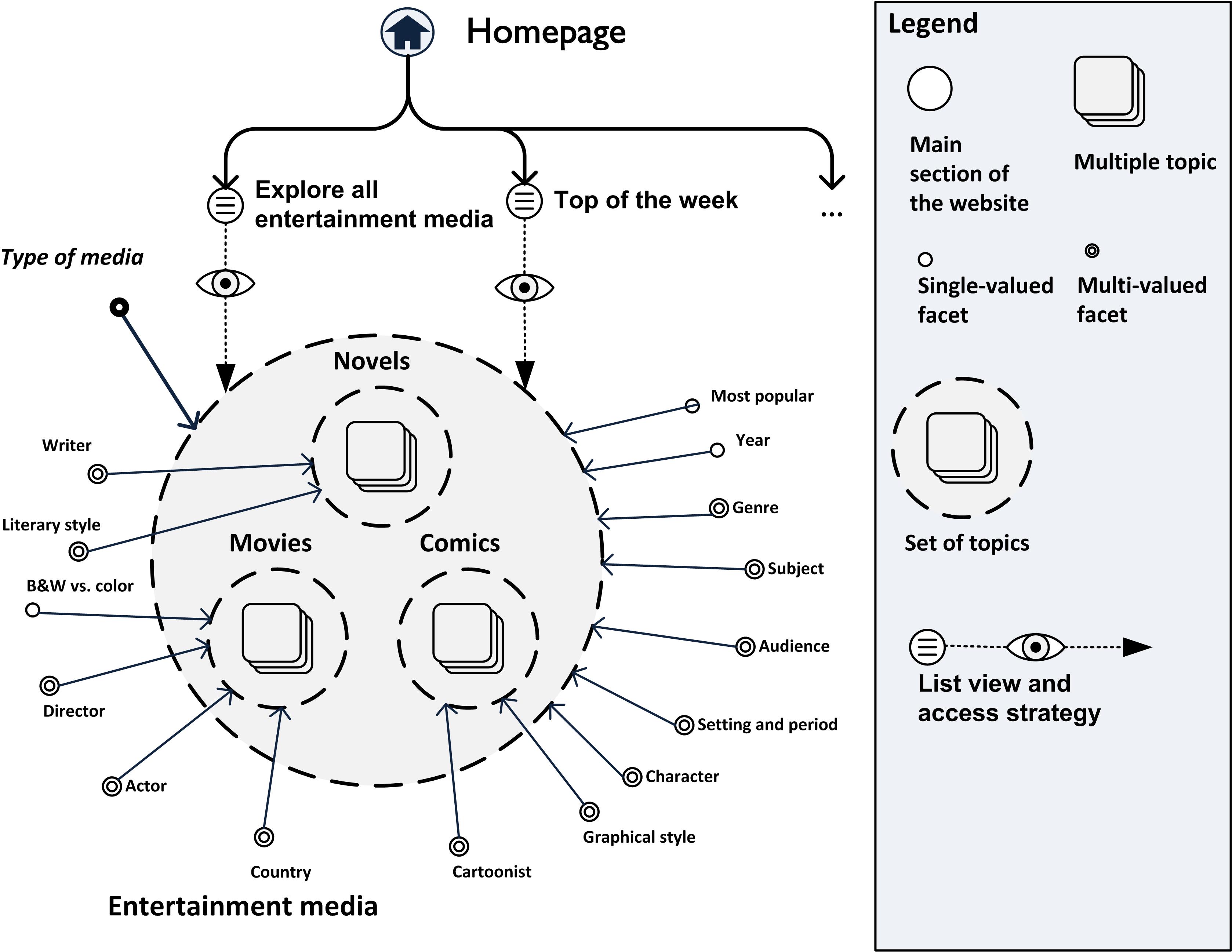
Figure 3. An example of a SEE-IA based model
Figure 3 shows how content items (topics) of different type can be explored separately or together (e.g. books only and/or movies), as they are enclosed in the same “Entertainment media” superset. Some facets (e.g. “Genre” and “Subject”) are shared by all topics while others are specific to a certain type of topic only (e.g., “literary style” is for novels, while “director” is for movies). Two different access strategies have been arbitrarily devised: a list of all entertainment media, and a list of “Top of the week highlights.” Both lists can be filtered using facets.
Now let us see how the flexibility allowed by the SEE-IA modeling strategy can be useful in a concrete and quite complex case. In our case study, very relevant pieces of information (the “multiple topics” in our model) are “soprintendenze” (i.e. highly independent local branches of the Ministry), “museums,” and “archaeological sites” (quite numerous in Italy!). Users may be interested in all three categories since they are all “cultural venues,” or in just one or two of them. These venues are distributed all over Italy, and granularity may range from regions to counties or exact locations, and they may be relevant for different cultural aspects, like “Romans” (Roman civilization), “Italics” (civilizations preceding the Roman conquest), “Magna Graecia” (colonization from Greece in Southern Italy before the Roman era), or Etruscan. Approximately 20 cultural categories have been identified. How can we represent this complex situation to the users? A traditional information architecture would group museums, sites and “soprintendenze” according to different criteria, but still the number of potential combinations would be too high to manage. A standard hierarchical solution (organized, for example, by geography/type/cultural aspect) would be highly unsatisfactory for most users. The site does offer a blind (i.e. without clues) search engine, like most large websites do. But it would work only for users such as domain experts who know quite precisely what they are looking for. The result of a query is a list of items in alphabetical order, which a non-expert user may scroll through, making some trial clicks on, and not get much from.
Figures 4 and 5 show the result of the SEE-IA approach to the problem.
In Fig. 4, all venues are shown at once, clustered by region and type (color - A). Specific types of venues (B), specific areas (C) and specific cultural aspects (D) can be browsed. The font size shows the relative relevance of the cultural aspects (“Romans” are the most important, followed by “Italics,” and so on).
In the interactive thematic map, the three types of venues (museums, “soprintendenze” and archaeological sites) are displayed at once, but individual types can also be selected from the top right menus. Geography is considered at different levels: regions (shown in the figure), provinces, and exact location (fig. 5). The map in Figure 4 is a multivariate graduated symbol map (Andrienko & Andrienko 1999): on each region a “circle” shows, by size and number, how many venues are there, with colors corresponding to the type of venue. At the bottom right words showing the cultural characterization (civilization or period of interest) for the current selection are shown: the size of the words in the tag cloud is proportional to the relevance and frequency, i.e. to the number of venues in the current selection, characterized by that parameter.
In Fig. 5, location (at area, region, province or precise level) is used to organize Museums, Archaeological Sites and “soprintendenze.” The “Period and Civilization” (e.g. Romans, Greeks, Middle Ages) facet is used in order to classify all kinds of venues. Venues can be shown through thematic maps or just listed (as more traditional websites do).
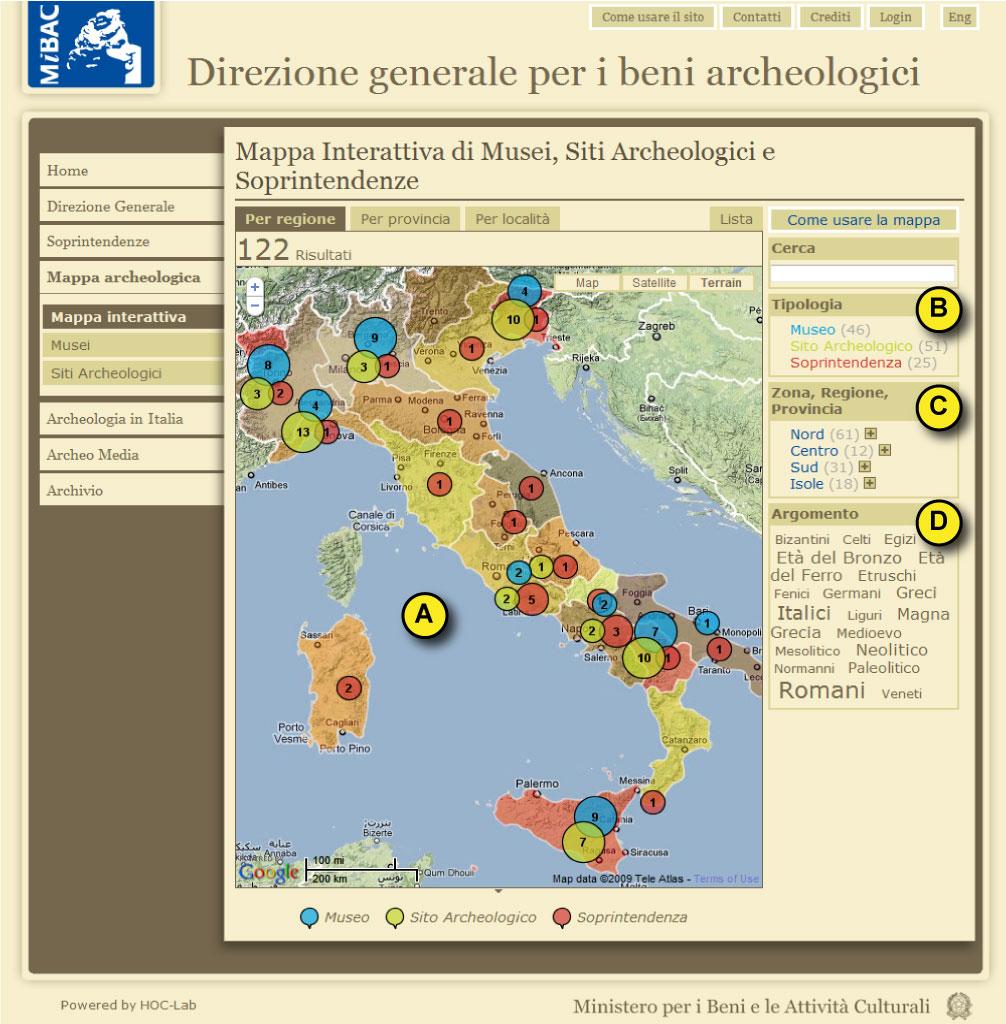
Figure 4. Thematic interactive map of archaeological venues in Italy.
Let us examine in mode detail the opportunities offered to the user experience.
Findability Expert users can easily locate the venues of the type (e.g. museums), geographical area, and cultural characterization (e.g. “Italics”) they are looking for.
“At a glance” sense making Any user, at whatever level of expertise, may immediately grasp where different types of venues are distributed in Italy, and see their cultural characterization.
Serendipity Non-expert users may discover, looking at the page in Figure 4, cultural characterizations unknown to them, or unexpected locations relevant for a cultural characterization (say “Etruscan”).
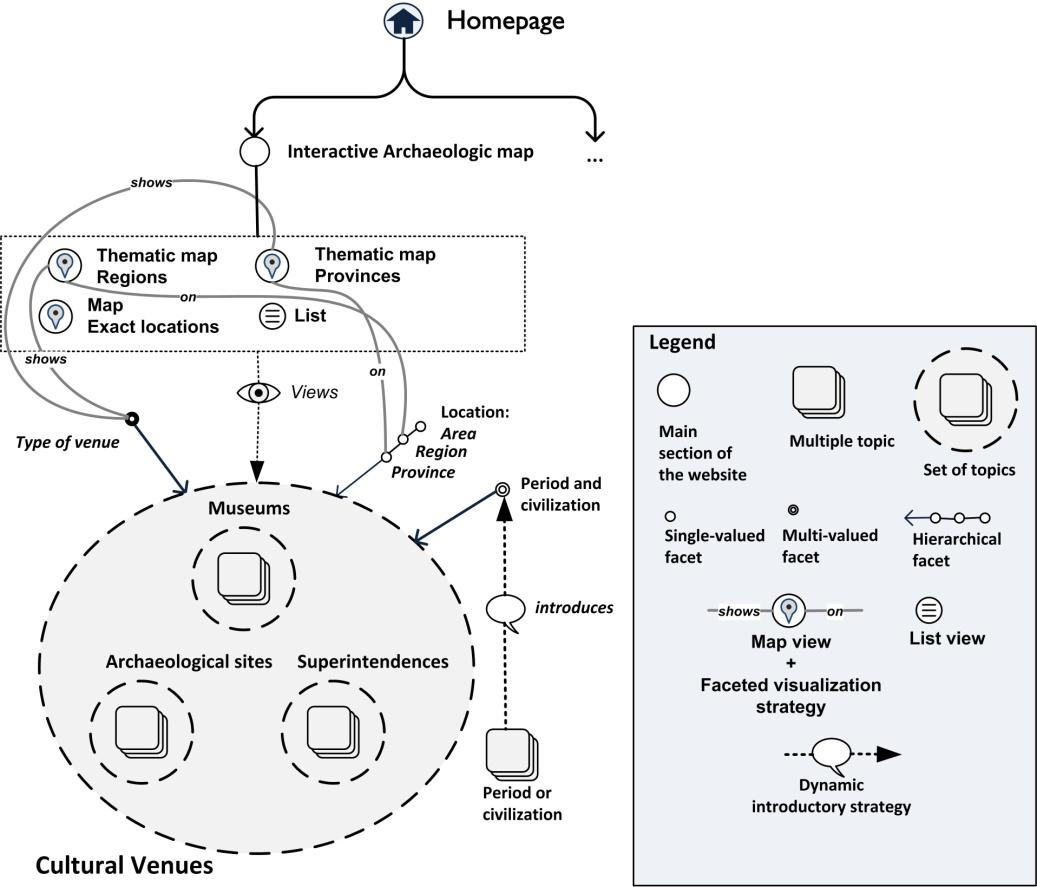
Figure 5. A portion of the SEE-IA model for the Directorate-General for Antiquities.
Branding and communication strength Users receive a strong communication message, i.e. the richness and wide distribution of the archaeological patrimony of Italy (one of the intended brand goals).
Playful discovery Expert and non-expert users are both likely to play with this engaging interface to discover cultural information. Selecting the Northern area of Italy only, for example, “Romans” is still the most important cultural word, while “Italics” fades down (fig. 6-A). Selecting the Southern area, “Magna Graecia” and “Italics” emerge as relevant too (fig. 6-B), while Celts disappear, since they were not present in that area. Concerning this, a remarkable educational effect can be noticed: the user acquires knowledge not only from predefined contents but also from something that emerges dynamically from the interaction and visualization per se. The geographical distribution of ancient civilizations is a piece of information she does not get by reading a text but rather by playfully interacting with the application. Serendipitous learning by doing, which is so typical of games (Gee 2005), is thus supported.
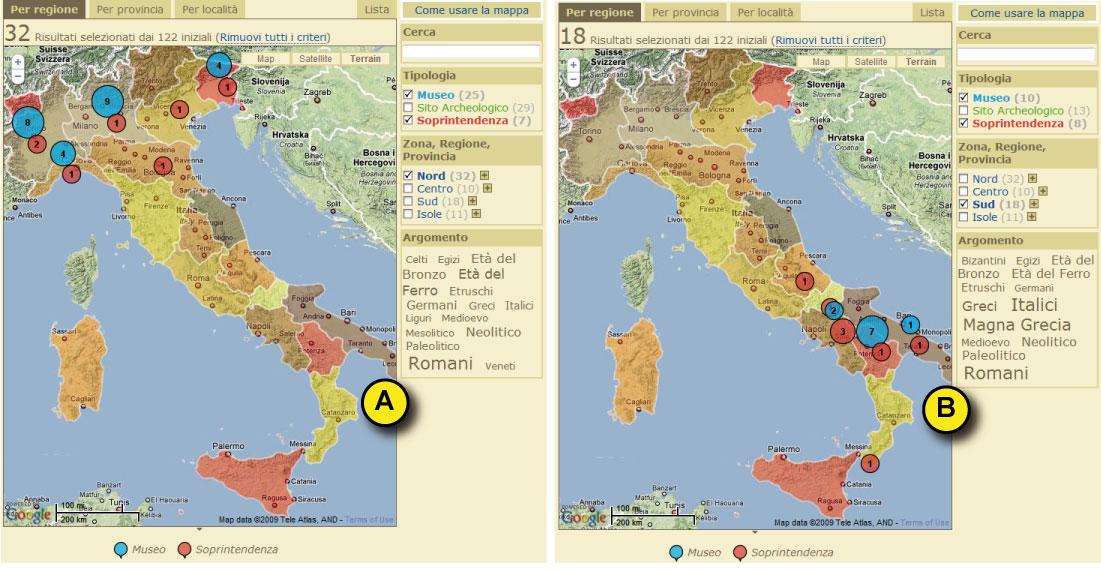
Figure 6. Browsing Archeology (Museums and Soprintendenze) in Italy.
In Fig. 6, tag clouds show the relative relevance of the different civilizations (e.g. “Romans” and “Iron Age” in Northern Italy, and “Italics” and “Magna Greece” in Southern Italy).
All the above, however, must be combined with the systematic navigation-exploration, that traditional information architectures provide. Let us assume, for example, that the user, after some exploration, focuses (by simple curiosity or with a precise goal in mind) on “museums” and “soprintendenze” in “Southern Italy” concerning “Magna Graecia.” She will get a traditional index (fig. 7-A), that can be also saved in pdf format. From there, a traditional guided tour (which is not what search engines usually provide) can be started.
Rich Internet Applications represent an ideal solution to support this kind of rich and playful user experience, since the fluidity and immediateness of responses to user selections is a strong requirement. Using traditional, non-RIA frameworks would result in longer time needed to refresh the page, and this would break the interactive flow of exploration, making it much less natural and engaging.
Designing Introductory Content for Dynamic Architectures
Groups of items, such as “museums and archaeological sites about Magna Graecia in Southern Italy,” are an important way to suggest to the user where relevant information is. A mere list of items, however, is often not sufficient. A traditional information architecture could (or should) provide a meaningful introduction, by explaining, for example, what Magna Graecia was and why there is a specific pattern of distribution of venues in that area. A traditional search engine would instead provide a dry list of items (hopefully suitably ranked), leaving to the user the task of making a sense out of it. Dynamically created groups of items, such as a list of search results, may be relevant but also disconcerting if not properly introduced. It is a challenge to provide salient introductory information on top of these dynamically created groupings, to give the user the elements needed to understand the relevance of these groupings and make informed decisions.
In the example above described, the user must be helped to understand each term of the title (like “Magna Graecia” or “soprintendenze”), as well as the resulting group of items. To this end, explanatory text can be associated with each facet value (e.g. in Fig. 5 the “period or civilization” topics serve as introduction to the corresponding facet). This text can be used in several situations: as a tooltip before making a selection (fig. 7-C), as an introductory text after the selection is made (fig. 7-B), or whenever the user needs it. The combination of the explanations of the individual terms can greatly help users make sense of their current browsing experience. Finally, it is possible to design a specifically-tailored introduction for particularly interesting combinations of facet values: some “featured searches” can be added periodically to the website to entice the users to visit the site again. Interesting groups of items (corresponding to some search combinations), deserving an ad hoc introduction, may emerge from website usage statistics (e.g. the most popular or the most intriguing search combinations). With such a strategy a combination of search mechanisms and a partly pre-planned information architecture will emerge over time.
Designing for Rich Navigation Context and Orientation
Once users locate a set of items, for example “museums and archaeological sites about Magna Graecia in Southern Italy,” a number of typical actions may follow: glancing through the index (i.e. the list of items); selecting one entry of the index and looking at the details of the corresponding item; navigating to the next item (guided tour); navigating from one item to related information (hypertext navigation); or navigating back to the index for selecting another item To support these activities, context and orientation are critical and need to be constantly offered to the user. If traditional, well-engineered information architectures are very good at this, search engines, in general, are not. In addition, there is the issue of life span: how long should a dynamically built set of items remain available? One session? Several sessions?
In SEE-IA, dynamically generated groups of items are first class citizens. They can be used with consolidated navigation patterns (such as indexes and guided navigation: see Bolchini & Paolini 2006) so that (i) the passage between the two types of navigation is natural and (ii) the orientation, i.e. the user awareness or the current context and status of navigation, is still ensured.

Figure 7. Magna Graecia museums and soprintendenze in Southern Italy. Interactive list (A) with introductory information (B), an interactive tooltip (C), and search history (D)
Dynamically generated sets such as the one in Figure 7 can become temporary indexes, valid within the current session only, or can become a permanent feature of a customized version of the website, available to the users who generated them. As far as links and hypertext navigation are concerned, there is no difference between the predefined set of items and the dynamically generated one. Customized Information Architecture is what we are aiming at, and what is provided by this application.
Implementation Issues
The flexibility of SEE-IA allows for several implementation strategies, including the usage of existing, reliable technologies. For the presented case study, we employed the EzPublish CMS (http://ez.no) to manage the contents of the website. The faceted search and advanced interactive visualizations were based on Simile Exhibit (Huynh Karger and Miller 2007, http://www.simile-widgets.org/exhibit), i.e. a lightweight, client-side JavaScript framework aimed at facilitating the publishing of small-medium size collections of semi-structured metadata. Simile Exhibit also takes advantage of Google Maps APIs (http://code.google.com/apis/maps) for displaying items on a map. For scalability purposes alternative solutions could rely on search servers such as Apache Solr or other consolidated frameworks for faceted search and search in general.
Conclusions and Future Work
RIAs are not just more fluid interfaces on top of current websites: they provide the possibility of creating more effective applications. These applications may be new but - as we have shown - they can also be old ones revisited. In this paper we propose the creation of a new generation of very large content-intensive websites, coupling traditional engineered information architectures (offering strong organization, powerful navigation, context orientation, branding, and communication strength) with features provided by search patterns and advanced interfaces.
The unique contribution of the proposed design strategies is that they provide a way to seamlessly integrate existing paradigms to support exploratory user experiences, where ill-defined user’s goals - exploring and making sense of the complexity - are in constant dialogue with the goals of the application stakeholders - highlighting salient content and communicating values and brand messages.
In particular, sense making becomes an autonomous part of the exploratory experience, instead of being just one more component. Our thematic map can be used not only as a means for gaining access to a specific piece of information (e.g. information about the museum X), but also as a tool to understand the Italian cultural heritage as a whole, for example how civilizations are correlated to the type of venue or specific area. In other words, instead of being mere access structures, groupings may become the primary focus of the users’ interest.
The user experience cannot be defined as a search or navigation experience anymore: it becomes something more complex, a semantic browsing and a sort of intuitive exploratory data analysis. We are currently working on emphasizing this aspect, introducing within the approach additional visualization strategies borrowed from statistical graphics, such as matrix charts.
The design strategies proposed by SEE-IA are also general enough to be easily applied to other IA design contexts which are characterized by content-intensive user experiences, where these requirements are important to address. For example, the integration of faceted search and traditional information architectures in an interactive map can be applied to all those situations in which highly structured and interconnected architectures would benefit from a visual representation of their facets (which is traditionally only used for search-oriented purposes).
As another example of general applicability, the re-purposing of introductory content to enhance exploration leverages content elements which are typically already developed for other contexts (e.g. list pages), and that, with these strategies, can be meaningfully and more pervasively reused and valorized throughout the application.
Our current research is aiming at developing new ideas for large and very large websites. Traditional information architecture has its own merits, but its inadequacies require blending it with novel approaches. We also try to balance a classic design approach, where the designer specifies exactly what the user can or cannot do, with a totally non-structured approach, as for example when the user is left with a search engine. Experiences like “at a glance understanding” require a careful blending between designer’s guidance and user’s choices and preferences.
Also, we want to make sure that designers keep adequate control over what the users will get in terms of content, brand, and feeling. In this tension (between keeping control and letting the user go), we are looking for a non-trivial dynamically customized navigation, where available navigation paths are a natural combination of the user’s needs, desires, expectations, and of the designer’s choices. Future research focuses also on two more general issues: classification and relevance of content items. In many application domains, assigning a facet value to a content item can be quite arbitrary. What does it mean, exactly, that an Italian church dates back to “middle ages”? Does it mean that it was built then, and no additions were made after? In Italy, it is often the case that a church is built upon Roman ruins (re-using the ruins themselves), and that it gets changed through the ages (for example, getting additional chapels during Renaissance or Baroque times).
Should that church be classified as “Roman” or related to “Renaissance” too? The choice is not easy: if the church is not classified as relevant for Renaissance, some users may be satisfied but others may be deceived (e.g. experts looking for Renaissance chapels!). The solution we are exploring is “scale classification;” we mean to score facet values not on a binary scale (0 vs. 1, yes vs. no) but on a fuzzy scale (e.g. evaluating the relevance in percentages). Getting back to our example, the church may be classified as 20% relevant for Renaissance. Scale classification is certainly difficult for content providers, but it may support a better user experience.
A related issue is contextual relevance related to the number of items. Let us consider our archaeological case study: how many content items (“instances of multiple topics” in our terminology) should we consider? One thousand of the most important items are more than enough to provide an overall understanding, a leisured browsing experience, and successful brand communication.
This implies that, out of a hypothetical total of 10.000, ,000 items should not be considered. So it may happen that a user focusing on Italy may not be offered the archaeological Museum of Milan (a beautiful, small institution), since it does not belong among the 1,000 most relevant, at Italian level, selected items. But it may surface up if the user focuses on Lombardy region only (where Milan is located). Geography is not the only facet that can modify relevance: the archaeological Museum may be relevant also for a user focusing on Roman Civilization.
We call this approach “fisheye relevance,” in which content items are hidden or shown according to several criteria. It does not order a content item as being high or low in ranking, it enables it to be considered or not. In other words, we mean to pursue our overall goal: overcoming the limitations of navigation and search experiences, and creating a new generation of information architectures that may provide a variety of rewarding user experiences.
References
- Andrienko G. and Andrienko N. (1999). Interactive maps for visual data exploration. Journal of Geographical Information Science. Vol. 10, (4). Pp. 335-374.
- Bolchini, D., Garzotto, F. and Paolini, P. (2007). Branding and Communication Goals for Content-Intensive Interactive Applications. Proceedings of 15th IEEE International Conference on Requirements Engineering. Pp. 173-182.
- Bolchini, D., Garzotto, F. and Paolini, P. (2008). Value-Driven Design for «Infosuasive» Web Applications. Proceedings of 17th International World Wide Web Conference. Pp. 745-754.
- Bolchini, D., Garzotto, F. and Sorce, F. (2009). Does Branding Need Web Usability? A Value-Oriented Empirical Study. Proceedings of the 12th IFIP conference on Human-Computer interaction. Pp. 652-665.
- Bolchini, D. and Paolini, P. (2006). Interactive Dialogue Model: a Design Technique for Multi-Channel Applications. IEEE Transactions on Multimedia. Vol. 8, (3). Pp. 52-541.
- Ceri, S., Fraternali, P., Bongio, A., Brambilla, M., Comai, S. and Matera M. (2002). Designing Data-Intensive Web Applications. Morgan Kaufmann.
- Crystal, A. (2007). Facets Are Fundamental: Rethinking Information Architecture Frameworks. Technical Communication. Vol. 54, (1). Pp. 16-26.
- Garzotto, F. and Paolini, P. (1993). A model-based approach to hypertext application design. ACM Transactions on Information Systems. Vol. 11, (1). Pp. 1-26.
- Gee, J.P. (2005). Good video games and good learning. Phi Kappa Phi Forum. Vol. 2, (85).
- Hearst, M. A. (2009). Search User Interfaces. Cambridge University Press.
- Hearst M., Smalley, P. and Chandler, C. (2003). Faceted metadata for information architecture and search. Proceedings of the SIGCHI conference on Human factors in computing systems 2003. Pp. 401-408.
- Huynh, D. F., Karger, D. R. and Miller R. C. (2007). Exhibit: Lightweight structured data publishing. Proceedings of the 16th International WWW Conference. Pp. 737-746.
- Koch, N., Knapp, A., Zhang, G. and Baumeister, H. (2008). UML-Based Web Engineering: An Approach Based on Standards. In Olsina, L., Pastor, O., Rossi, G., Schwabe, D. (eds) Web Engineering: Modelling and Implementing Web Applications. Human-Computer Interaction Series. Vol. 12. Springer. Pp. 157-11.
- Marchionini, G. (2006). Exploratory search: from finding to understanding. Communications of the ACM. Vol. 4. Pp. 41 - 46.
- Morville, P. (2007). Ambient Findability. O'Reilly.
- Morville, P. and Callender, J. (2010). Search patterns. O'Reilly.
- Park, J. and Kim, J. (2000). Contextual Navigation Aids for Two World Wide Web Systems. International Journal of Human-Computer Interaction. Vol. 12, (2). Pp. 13-217.
- Quintarelli, E., Resmini, A. and Rosati, L. (2007). Facetag: Integrating bottom-up and top-down classification in a social tagging system. Proceedings of the 8th ASIS&T IA Summit 2007.
- Rosenfeld, L. and Morville, P. (2006). Information architecture for the World Wide Web. O'Reilly.
- Rossi G., Schwabe, D. and Guimaraes, R. (2001). Designing personalized web applications. Proceedings of the 10th International WWW Conference. Pp. 275-284.
- Sacco, G.M. (2006). Some Research Results in Dynamic Taxonomy and Faceted Search Systems. SIGIR 2006 Workshop on Faceted Search.
- Tunkelang, D. (2009). Faceted Search, in Marchionini, G. (ed.), Synthesis Lectures on Information Concepts, Retrieval, and Services. Morgan & Claypool Publishers.
- Weinberger, D. (2007). Everything is Miscellaneous: The Power of the New Digital Disorder. Times Books.
